The Illusion of Security
Business rules and account status often lead to a false sense of security and offer fraudsters significant opportunity. That's why VALID analyzes behavior.
Business Rules & Account Status vs. Behavioral Analytics
In military circles, the greatest form of deception is to appear to your enemy as if you are doing EXACTLY what they expected you do. This lulls them into an illusory sense of security as they are mistakenly confident in their own intelligence. When true plans are revealed, it is often too late for your enemy to react.
The adage above is equally applicable to financial risk management. Fraudsters have become more sophisticated in their tactics, but the industry has not kept pace with this dynamic threat.
Account takeover, phishing scams, and account/device spoofing are flooding financial institutions (FI’s) along with traditional forms of fraud such as fake checks. FI’s are still to a large degree combatting these more advanced forms of fraud with the outdated concepts of business rules and account status.
In theory, business rules should reduce fraud. Most personal and business accounts have a predictable pattern of behavior. Risk surrounding recurring dollar amounts, withdrawal timing, and deposits could logically be managed by a static set of predictable rules. Examples of these business rules are authorized accounts, maximum dollar amounts for specific transactions, and funds availability policies. The same approach applies to account status as a go/no go decisioning factor. By pre-determining which accounts are cleared for certain transactions the random bad actor can be stopped.
The operative word in the paragraph above is “predictable”. The worst characteristic of a fraud solution is to be predictable. If fraudsters know which accounts are considered “good” or where the business rules are drawn, then you can expect them to have a plan to exploit it. As stated at the opening of this article, business rules and account status often lead to a false sense of security and offer fraudsters significant opportunity. By making their fraudulent transactions on pre-approved “good” accounts, a massive amount of fraud can occur before it is detected.
For example, let’s assume there are 20 distributions from an account the last week of every month, each of them between $1500 and $2500 dollars. There are business rules in place to cap the timing and maximum range of those distributions. If a fraudster knows this, it is a straightforward exercise to create a new account to which $2200 is distributed every month. Only after a cash discrepancy is noticed or an audit occurs would that fraud be caught, which might be several months down the path.
How do fraudsters learn these business rules and account status? The short answer is patience. Given the number of high-profile data breaches (Anthem, Target, etc.) there are millions of accounts whose information is available for sale. Separate from these well publicized breaches, accordingly to data security firm Varonis it takes approximately 187 days for a break to be detected regardless of firm size. This gives fraudsters ample to time observe patterns firsthand across multiple accounts. Independent of this approach, fraudsters have sophisticated & automated process designed to probe accounts - often through low dollar transactions. While the fraudsters tactics will vary, they key take away is that the time they have to analyze account rules essentially renders them useless.
Additionally, there is an extensive library awaiting any would-be fraudster right on their phone. Social media is a bulletin board of tips and tricks, recruiters, and how-to videos to defraud your institution. They know your vulnerabilities and are broadcasting them to the masses. Many of these focusing on fraudulent check deposits.
So, if static defenses are insufficient what options are available to FI’s to combat this ever-more complex threat? The good news is that behavioral analytics offers a unique lens to identify the bulk of fraud attempts. By using AI tools and machine learning focused on behavioral patterns, fraudsters can be identified across multiple fraud strategies and are unable to identify significant gaps.
Put simply, a machine learning model uses training data to learn how to make predictions on future requests. When new trends are seen, retraining the model ensures that the model can react to these trends appropriately. The image below shows high level what methodology machine learning uses.
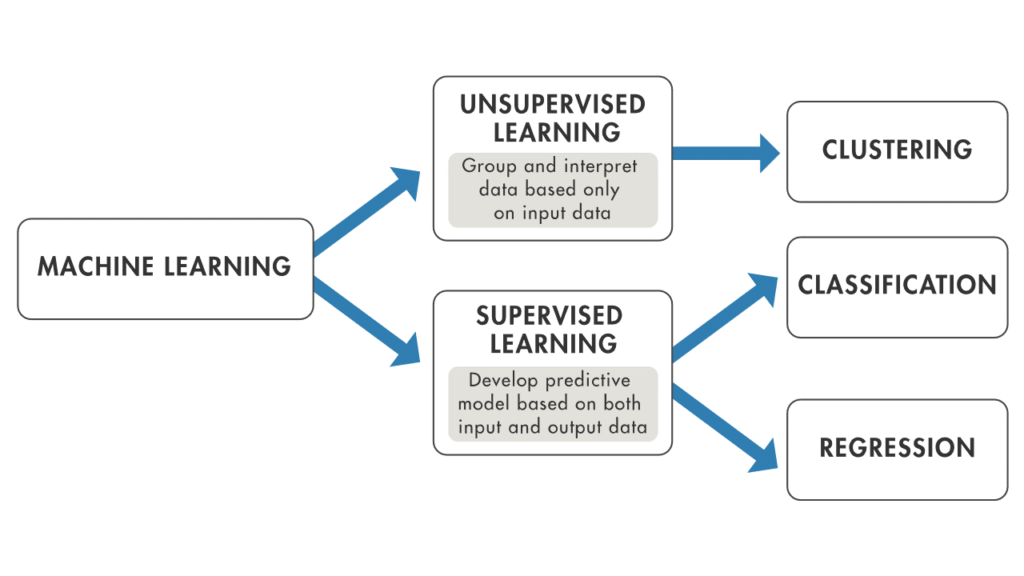
To the point made in the graphic above, Supervised Learning is the training of an ML algorithm on a data where both the feature (a data point) and the label (good/bad/fraud/clear) are available. The ML algorithm uses the features and the labels as an input to map the connection between features and labels. When the model is trained, labels can be generated by the model by only providing the features. A mapping function is used to provide the label belonging to the features. The performance of the model is assessed by comparing the label that the model provides with the actual label.
In Unsupervised Learning there is no dependent variable (or label) in the dataset. Unsupervised ML algorithms search for patterns within the features. The algorithm links certain observations to others by looking at similar features. This makes an unsupervised learning algorithm suitable for, among other tasks, clustering (i.e. the task of dividing a dataset into subsets). This is done in such a manner that a label within a group is more like other observations within the subset than an observation that is not in the same previous group.
In reference to the learning models above, VALID’s team works with you to leverage the previously obtained human-generated intuitive lessons learned. These hard-earned lessons help provide the building blocks for Supervised Learning. More than a simple black box, VALID’s team combined with next-generation machine learning can provide your business a true point of marketplace differentiation.
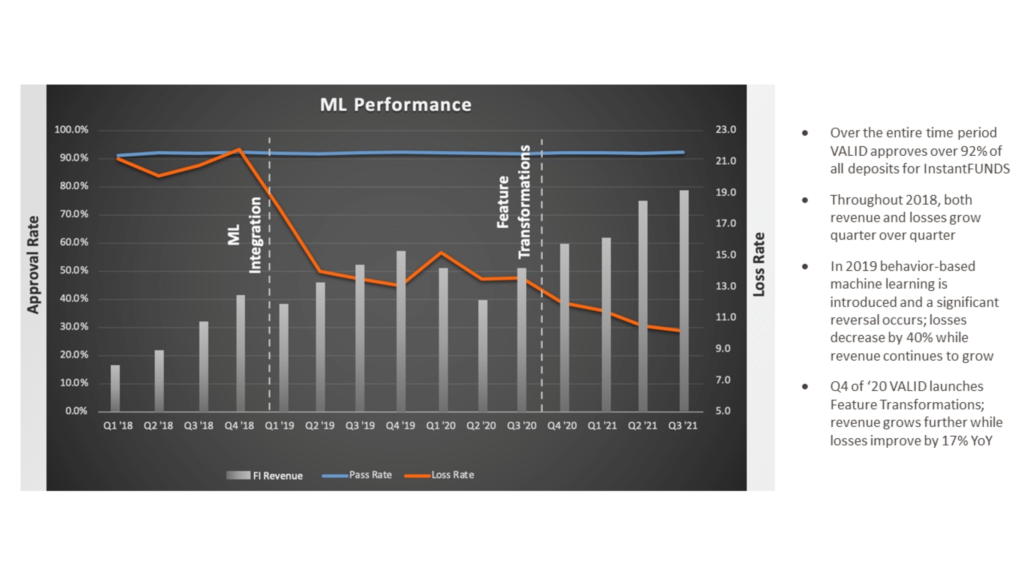
When talking about machine learning, the emphasis is often (erroneously) put on the “machine” instead of the “learning. In the example below, VALID’s Decision Science team demonstrated consistent improvement over time, driving revenue for the FI while decreasing losses (as the team focused on improving the performance of the models).
A machine learning model, like any learning system, requires data to evolve. This obvious statement does then lead to what type of data is optimal for a model that can adapt as quickly as an AI-enabled one? Before answering that question, let’s review the two types of data available to FI’s: third-party and first-party.
Third party data is aggregated by other companies and then either sold or provided to a larger consortium. This kind of information reflects what is happening but not the why. Think of this data as raw facts and figures (account status, dates, amounts, etc.). You will likely have data that looks similar at this high level but without a full understanding of context with it does not mean the same thing in a business setting. First party data captures each individual’s unique flow through a digital experience in its totality. Through first-party data you can develop a full understanding of how markets are truly interacting with your business.
While first party data is valuable, what is the role of customer’s stated intentions? Said another way, why not spare your business the effort of compiling the data and simply ask them? As a customer I can describe my normal process of depositing a check and the circumstances under which I conduct that transaction. The simple truth is that customers’ actions convey much more meaning than words. To illustrate this point apocryphally, there are stories in the marketing world surrounding Sony’s release of the portable stereo (colloquially referred to as the “boom box”) in the late 80’s. While working with focus groups to determine the desired color patterns, the groups consistently said they wanted bright, vibrant patters. Sony, however, was curious what their actual decision making would be. After several sessions, they started offering free stereos to the participants in the vibrant colors and basic black. Despite their feedback to the contrary, by far the basic black model was chosen over the bright colored options. This example demonstrates the value of making decisions based on empirical data.
Now that we know the value of each type of data, the next critical question becomes what business goal are we trying to reach with that data? What is the model attempting to actually do? This is where we must examine the role of role of key performance indicators (KPI’s).
For business, key performance indicators are the strongest and most defensible tool in decision making. They identify the progress of the work of the team, the progress of the product and the overall business.
KPIs should be used to celebrate success and identify risk. Conversely, the lack of KPIs leave a product manager blind to what’s going on and show a weakness in management style. To go deeper into this topic, Product managers should also monitor customer related KPIs as an indicator of how well the sales and customer success engagements are working. While the business results are the true “what”, the customer success metrics often provide insight as to the “why”. If customer velocity is reducing, is there a new competitor? Is it a pricing issue? Is it a customer communications/expectation issue? If customers are leaving (churn or attrition) then a deep dive should immediately ensue to explore remediation activities.
To continue down this path, if we have the data and the associated KPI’s, how will we leverage the machine learning model effectively? There are numerous options available, but we will discuss A/B Experimentation, funnel analysis, and segmentation.
A/B experimentation lets you make decisions with confidence. Not sure about a particular risk profile? Wondering if a future product feature is worth the cost and trouble of full implementation (and communication to customers)? Instead of making changes to your product based on intuition, you can determine the best course of action using tangible data generated from market-based behaviors. Armed with user behavior data, you can make big-picture adjustments that improve the customer experience without the larger associated risk.
Funnel analysis is a complimentary approach to A/B experimentation. Every choice a customer (or fraudster) takes while operating within your environment presents an opportunity for progress or drop off. Funnel analysis enables you to examine every stage of the journey so you can fix pain points and/or confirm winning / profitable experiences. As your business grows, you’ll likely have more funnels to maintain and optimize.
Segmentation allows you to discover trends and patterns by comparing groups of users and behaviors over time. One of the strongest benefits of machine learning is its ability to look at data across multiple verticals. For example, your fraud prevention measures will likely find early success with a certain type of fraud. If you segment that data and look for outliers, the model can locate new types of fraud that static models did not catch. Then you can de-incentivize new fraudsters while ensuring a high level of legitimate customer satisfaction.
Through their supervised method, VALID has been able to identify up to 95% of FI deposit charge offs. The VALID model leverages Bayesian principals (specifically Bayesian inference) to guide risk principals and by focusing on establishing the most critical components of behavioral trends VALID can identify fraud and predict future performance with incredible accuracy. The predicative ability of this approach helps FI’s of all types level the playing field with fraudsters who have the advantage of time.
Let us guide you through!
Talk to an expert
